https://www.safaribooksonline.com/library/view/git-essentials-livelessons/9780134655284/
Git Essentials LiveLessons
LESSON 1
Installationinstall git from https://git-scm.com/download/win
install sublime from https://www.sublimetext.com/3
from git bash set your global variables
//set global user name
git config --global user.name "hassan jamous"
//set global email
git config -global user.email "'hassan.jamous@gmail.com'"
//set global color
git config --global color.ui "auto"
//set global editor to sublime
git config --global core.editor "'C:\Program Files\Sublime Text 3\sublime_text.exe' -w"
you can view your global configuration
git config --list
LESSON 2
create a git repositoryyou can create a git repository in any folder,
cd to the folder and type
git init
git will create a .git hidden folder in this folder and all subfolders, you can type
ls -a to check
Branch Master
when you create a new git repository, you will be working on the Master branch.
Untracked, Staging and Commit
when you create a new file in your repository, the file will be in Untracked.
to track the file you type
git add FILENAME
or you can use
git add .
to add all the files to the staging area
after you add the file the file is in the staging area.
to commit your changes, which means save it to the branch you type
git commit -m "commit message"
to check the commit log
git log
Now if you change a file, the file will NOT be in the staging are, you should add it then commit.
The HEAD
the HEAD is your last commit, so when you commit new changes you are moving the HEAD, to the new commit
Check the differences
if you change the file, and before moving the file to the staging area. you can compare your changes with the last commit by typing
git diff
if the file is already in the staging area you should type
git diff --staged
after you commit you can compare with the previous version by
gid diff HEAD~1
which means compare with one commit before the head, you can use HEAD~2 or 3 ....
also you can compare with commit id, if you use
git log
you will git something like
commit 5dbed2e0bcd7bdb844d6a6fdfc6519b9f5da7e31
Author: hassan jamous <hassan.jamous@gmail.com>
Date: Wed Nov 16 19:00:50 2016 +1100
second commit
commit c39fbd23776eb5e569bff21b5bd8d05eacb1facd
Author: hassan jamous <hassan.jamous@gmail.com>
Date: Wed Nov 16 18:42:30 2016 +1100
first commit
you can use the commit id to compare the differences
git diff c39fbd23776eb5e569bff21b5bd8d05eacb1facd
MOVING your HEAD
you can move your head between commit by using git checkout.
for example you can move your head to the previous commit
git checkout HEAD~1
if you type git status here , it will tell you that the head is deattached and now is pointing to the previous commit
$ git status
HEAD detached at c39fbd2
nothing to commit, working tree clean
to go back to the last commit type
git checkout master
sure you can also checkout to commit id
git checkout c39fbd23776eb5e569bff21b5bd8d05eacb1facd
HOW TO GET THE PREVIOUS VERSION of a file
lets say you want an old version of a file, you simply checkout that file from the commit you want
git checkout HEAD~1 readme.txt
notice here that you are not moving the head, you just telling git that i want the file from HEAD~1
of course you can type
git checkout c39fbd23776eb5e569bff21b5bd8d05eacb1facd
now if you check git status, you will see that the file is modified and in the staging area,
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: README.txt
now you can commit your new changes.
Deleting a file
when you delete a file, the file delete action will not be in the staging area, you can confirm the delete simply by typing
git add
to add it to the staging area, then
git commit -m 'we deleted the file'
to commit
no if you want to reverse your changes, you dont want to add them to the staging area, you should type
git checkout master readme.txt
notice that we returned to the master version
Moving a file from a staging area to out of the staging area (undo the git add)
to move the file from the staging area type
git reset HEAD readme.txt
undo your changes
if you make a change, it is not in the staging area, if you want to undo the change
git reset --hard
Adding new folder to git repository
if you create a new empty folder, you will notice that git will not recognise that, you should have a file in the folder to be recognised.
that's why people create a .gitkeep file inside empty folder, git will recognise the folder, the .gitkeep will be hidden so normal users will not see it.
of course you can see the hidden file from the bash, by running ls -a
ignore files
to ignore files from git, you should create
.gitignore
file on the root folder of the respoitory, inside this file you can add the files or patterns that you would like to ignore.
force ignored file to be committed
to force an ignored file to commit
git add -f FILENAME
LESSON 3
GIT is structured this way

as you can see, you have a local copy, and you have remote, remote could be GITHUB, GITBUCKET, GITLAB or anything that follow git structure
you can have multiple remote, however the primary Remote is called origin (this is a convention)
you push or pull from remote
adding a remote
1- create a repositroy on github
2- we will use this repository as remote
3- we will add the remote, and it is gonna be our primary we will call it origin

git remote add origin http://github.com/hassan.jamous/SomeStuff.git
as you can see we named this remote ORIGIN, you can call it whatever you want, but as it is the primary we are following the convintion ==> it should be called remote.
now you need to push your repository to GITHUB
git push origin master
which means i want to push my master to remote called origin.
it will ask you for github username and password
checking what remote do you have
you can use
git remote -v
to get the list of remote repository that you have, you will get something like
$ git remote -v
origin https://github.com/hassan-jamous/SomeStuff.git (fetch)
origin https://github.com/hassan-jamous/SomeStuff.git (push)
as you can see, for each remote you have to entries, one to fetch the code and another to push the code.
USE SSH to connect to github
any change that you wanna do on github, you need to provide a username and password.
in order to solve this, you should use ssh rather than http url to connect to github
to do that
1- go to the root folder and create .ssh folder (on linux ~/.ssh, for windows C:\Users\Hassan)
2- cd to that folder
3- type ssh-keygen
4- you will receive this message Enter file in which to save the key (/c/Users/hassa/.ssh/id_rsa):
5- put the file name like id_rsa
6- then you will get the following messgae
Your identification has been saved in id_rsa.
Your public key has been saved in id_rsa.pub.
The key fingerprint is:
SHA256:RNSv2YIE5i3F4CXEIE074NFTJ2825CTOeH4YEv52/Mc hassa@LAPTOP-RULLPJAV
7- open id_rsa.pub
8- copy the key
9- go to github, open settings menu then SSH and GPG keys

10- add a new key, and copy the key.
11- now git the ssh location from git

and type
git remote add origin SSHLOCATION
HOW TO PUSH YOUR CHANGES TO GIT HUB
so now lets say you updated a file, you committed the changes, these changes will be stored locally, to push these changes to git hub
git push origin master
now the file will go to github
Pulling changes from GIT HUB
you can edit files on git hub directly, lets say you edited the file from git hub or you want to pull the latest changes
you can type
git pull origin master
Conflicts
when you push your changes, you might git an error, which will say that a conflict has happened because you dont have the latest version.
you should pull the latest changes and then push
git pull origin master
git push origin master
when you pull auto merge might not be possible so you should handle this manually
Creating a new branch
to create a new branch you can typ
git branch BRANCHNAME
this will create a branch from where you are, so if you are on master the branch will be created from master.
or you can type
git checkout -b BRANCHNAME
to list the list of branches you have
git branch -a
to move from one branch to another
git checkout BRANCHNAME
to delete a branch
git branch -d BRANCHNAME
in order to force delete a branch (in case there is some work on this branch that is not committed yet)
git branch -D BRANCH NAME
use capital D
to merge change to the master branch , you should first checkout to that branch
git checkout master
then you can merge
git merge BRANCHNAME
HOW TO CREATE A PULL/MERGE REQUEST
when you have a new task,
1- checkout from the master branch
git checkout -b NEWJIRA
2-do the changes that you want
3- now we should push this branch to remote
git push origin NEWJIRA
4- go to github website and create a pull request, here you should specify the base branch and the branch that you want to be merged (base branch will be master, the branch to be merged is NEWJIRA)
5- someone will see the pull request, will review it and accept the request.
6- after this you can delete the NEWJIRA branch from your github.
now your merged the NEWJIRA branch to the master branch on github, which means you merged on REMOTE. you need to pull these changes to your local master
git checkout master
git pull origin master
now your master is similar to the remote master
SYNCHING YOUR REMOTE WITH LOCAL, FETCH AND PULL
when you type
git branch -a
you will get something like
$ git branch -a
* master
newBranch
testingBranch
remotes/origin/master
remotes/origin/testingBranch
as you can see, it lists the branches that you have locally, and the remote branches.
lets say that you went to github and deleted the testingBranch, so you are deleting the remote testingBranch
after you do that you should update your local repository in order to be synced with the remote, in order to sync your remote with local WITHOUT CHANGING YOUR LOCAL BRANCHES, you should use git fetch
git fetch
this will sync the remote branches, however in order to delete the missing branches as well you should type
git fetch -- prune
now if you type
git branch -a
$ git branch -a
master
newBranch
* testingBranch
remotes/origin/master
basically git pull is git fetch + git merge
LOG COMMAND
you can use
git log
to get the log of a branch
however there are too many information there. in order to see better version
git log --oneline
this will print one line for each commit
to print all commits
git log --oneline --all
to print a graph and to see which branch merged the changes
git log --oneline --all --decorate --graph
from the log you can see how the branches are related, it will tell you which branch is before another, and which branches are pointing to the same thing
for example, the following image tells us that development, origin/master and master branch are on the same level

and this image tells you that origin/master and master or on the same level
and feature/folder_documentation, origin/development and development are on the same level and in front of the master branch

when you push your changes, you might git an error, which will say that a conflict has happened because you dont have the latest version.
you should pull the latest changes and then push
git pull origin master
git push origin master
when you pull auto merge might not be possible so you should handle this manually
Creating a new branch
to create a new branch you can typ
git branch BRANCHNAME
this will create a branch from where you are, so if you are on master the branch will be created from master.
or you can type
git checkout -b BRANCHNAME
to list the list of branches you have
git branch -a
to move from one branch to another
git checkout BRANCHNAME
to delete a branch
git branch -d BRANCHNAME
in order to force delete a branch (in case there is some work on this branch that is not committed yet)
git branch -D BRANCH NAME
use capital D
to merge change to the master branch , you should first checkout to that branch
git checkout master
then you can merge
git merge BRANCHNAME
HOW TO CREATE A PULL/MERGE REQUEST
when you have a new task,
1- checkout from the master branch
git checkout -b NEWJIRA
2-do the changes that you want
3- now we should push this branch to remote
git push origin NEWJIRA
4- go to github website and create a pull request, here you should specify the base branch and the branch that you want to be merged (base branch will be master, the branch to be merged is NEWJIRA)
5- someone will see the pull request, will review it and accept the request.
6- after this you can delete the NEWJIRA branch from your github.
now your merged the NEWJIRA branch to the master branch on github, which means you merged on REMOTE. you need to pull these changes to your local master
git checkout master
git pull origin master
now your master is similar to the remote master
SYNCHING YOUR REMOTE WITH LOCAL, FETCH AND PULL
when you type
git branch -a
you will get something like
$ git branch -a
* master
newBranch
testingBranch
remotes/origin/master
remotes/origin/testingBranch
lets say that you went to github and deleted the testingBranch, so you are deleting the remote testingBranch
after you do that you should update your local repository in order to be synced with the remote, in order to sync your remote with local WITHOUT CHANGING YOUR LOCAL BRANCHES, you should use git fetch
git fetch
this will sync the remote branches, however in order to delete the missing branches as well you should type
git fetch -- prune
now if you type
git branch -a
$ git branch -a
master
newBranch
* testingBranch
remotes/origin/master
you will notice that the branch is deleted.
LOG COMMAND
you can use
git log
to get the log of a branch
however there are too many information there. in order to see better version
git log --oneline
this will print one line for each commit
to print all commits
git log --oneline --all
to print a graph and to see which branch merged the changes
git log --oneline --all --decorate --graph
from the log you can see how the branches are related, it will tell you which branch is before another, and which branches are pointing to the same thing
for example, the following image tells us that development, origin/master and master branch are on the same level

and this image tells you that origin/master and master or on the same level
and feature/folder_documentation, origin/development and development are on the same level and in front of the master branch

MERGE VS REBASE
in order to sync branches we used to do, git merge, what basically happens in git merge is the following
lets say you have this case
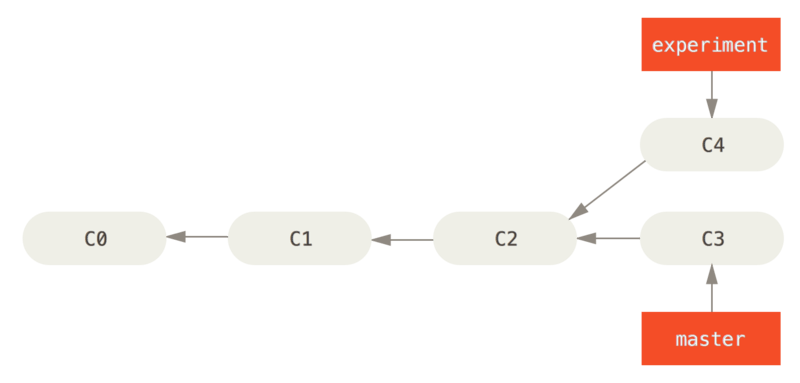
now when you merge you do the follwoing
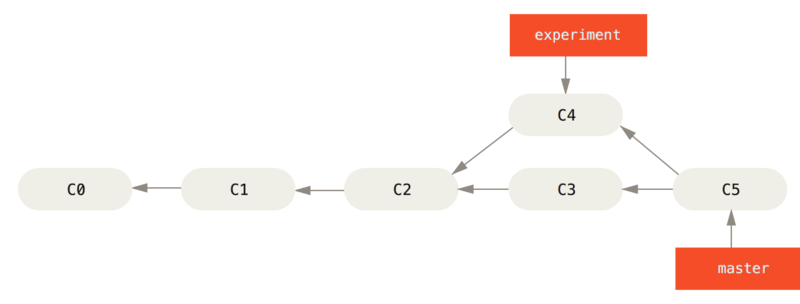
git checkout master
git merge experiment
and this what will happen
there is another way to merge which is rebase
lets say we have the following
rather than going to master and merge, we will do the following
git checkout experiment
git rebase master
now this what will happen, the output will be
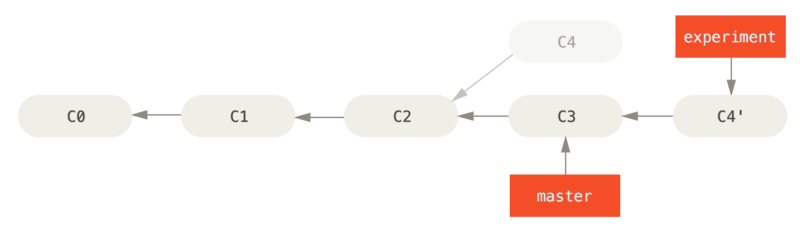
so we forwarded expermint to C4' infront of master
now we will type
git checkout master
git merge experiment
and this what will happen
there is another way to merge which is rebase
lets say we have the following
rather than going to master and merge, we will do the following
git checkout experiment
git rebase master
now this what will happen, the output will be
First, rewinding head to replay your work on top of it...Applying: added staged command
so we forwarded expermint to C4' infront of master
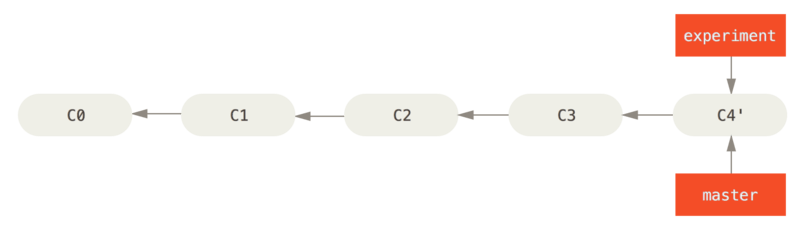
now we will type
$ git checkout master
$ git merge experiment
and the result
Lesson 4
Adding a collaborator
if you want to add someone to your github project so they can push and pull, go to your respository then choose setting -> collaborator, and then add the collaborator

now the collaborator should donwload the project. to do that use git clone
git clone REPOSITORY_SSH_LINK
this will donwload the project and will create the required remotes.
now the collaborator can push and pull
FORKING
if you have a big a project with many collaborator, you will not add all of them, the best solution for this is to FORK
fork means that you have project REMOTE and you will clone this project to your remote.
so when you fork it means that you are taking this project to your account (your remote), and when you push and pull you are basically doing that on your account not the project account.
by you do the update on your account (your remote) then create a pull request to merge it to the project remote
so, from GITHUB you can press the FORK button, now the project is forked and it is in your account.
you can copy the ssh link and use
git remote add origin SSHLINK
now do the changes and push it to your remote, then create a pull request to merge it to the project remote.
Now you when many people fork the project you will have a sync problem with a project.
to handle this you should add a new remote, this remote is the project itself,
so now you have your account remote (which we call it ORIGIN) and we should add the project remote (we call it upstream).
git remote add upstream PROJECT_SSH_LINK
very important that what you do is:
1- pull from UPSTREAM (i.e. get the latest version from project remote)
2- push to ORIGIN (i.e. push your change to your remote)
3- create a pull request to merge from ORIGIN to UPSTREAM

There are some situation when you resolve conflict,
you do git rebase
then you should do
git rebase --continue
and
git rebase --skip
and when you do rebase you usually have to force push
git push -f oringin master
git clone REPOSITORY_SSH_LINK
this will donwload the project and will create the required remotes.
now the collaborator can push and pull
FORKING
if you have a big a project with many collaborator, you will not add all of them, the best solution for this is to FORK
fork means that you have project REMOTE and you will clone this project to your remote.
so when you fork it means that you are taking this project to your account (your remote), and when you push and pull you are basically doing that on your account not the project account.
by you do the update on your account (your remote) then create a pull request to merge it to the project remote
so, from GITHUB you can press the FORK button, now the project is forked and it is in your account.
you can copy the ssh link and use
git remote add origin SSHLINK
now do the changes and push it to your remote, then create a pull request to merge it to the project remote.
Now you when many people fork the project you will have a sync problem with a project.
to handle this you should add a new remote, this remote is the project itself,
so now you have your account remote (which we call it ORIGIN) and we should add the project remote (we call it upstream).
git remote add upstream PROJECT_SSH_LINK
very important that what you do is:
1- pull from UPSTREAM (i.e. get the latest version from project remote)
2- push to ORIGIN (i.e. push your change to your remote)
3- create a pull request to merge from ORIGIN to UPSTREAM

There are some situation when you resolve conflict,
you do git rebase
then you should do
git rebase --continue
and
git rebase --skip
and when you do rebase you usually have to force push
git push -f oringin master
BRNACHING TECHNIQUES
check this url for branching http://nvie.com/posts/a-successful-git-branching-model/






















































































































